

The Problem with Traditional Chaos Engineering
Chaos engineering today is still largely a manual discipline. Teams write individual fault injection scripts — "kill this pod," "inject 500ms latency on this endpoint," "drop 20% of packets" — and run them one at a time during scheduled game days. The coverage is only as good as the scenarios engineers thought to write.
That creates a systematic blind spot: the failures you haven't imagined are the ones that will actually hurt you. Complex distributed systems develop subtle failure modes at the intersection of components — partial network partitions, cascading timeouts, memory pressure amplified by retry storms — that no human would naturally think to script.
Hermes was built to change that.
What Hermes Does
Hermes is an LLM-driven chaos engineering framework that uses autonomous agents to discover, inject, and report on resilience gaps in distributed systems — without requiring manual fault scripts. Given a description of your system topology and a target service, Hermes:
- Observes — queries the system's current state via tool-augmented MCP servers
- Reasons — uses an LLM to identify likely failure modes based on observed topology and traffic patterns
- Injects — applies targeted faults (latency, packet loss, pod failure, resource exhaustion) through infrastructure APIs
- Measures — captures system response: error rates, latency distributions, cascading effects
- Reports — generates a structured resilience report with findings, severity scores, and remediation suggestions
Architecture
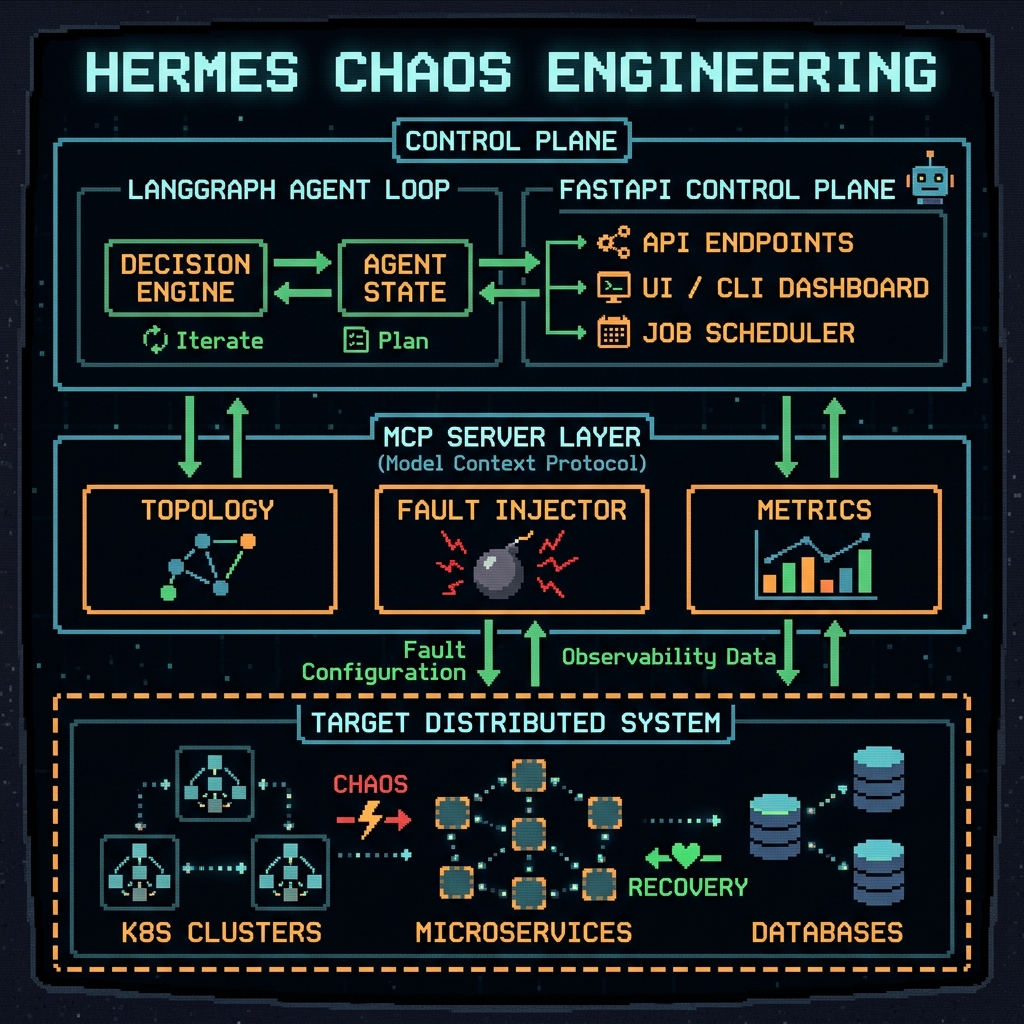
LangGraph Agent Loop
The core of Hermes is a stateful LangGraph graph that manages the agent's reasoning and tool execution cycle:
from langgraph.graph import StateGraph, END
from langgraph.prebuilt import ToolNode
def build_chaos_graph(tools: list) -> StateGraph:
"""Build the LangGraph orchestration graph for chaos agent."""
graph = StateGraph(ChaosState)
# Nodes: observe → reason → plan → inject → measure → report
graph.add_node("observe", observe_system_state)
graph.add_node("reason", llm_reason_about_failures)
graph.add_node("plan", plan_fault_injection)
graph.add_node("inject", ToolNode(tools))
graph.add_node("measure", collect_system_metrics)
graph.add_node("report", generate_resilience_report)
# Conditional edges allow the agent to loop or terminate
graph.add_conditional_edges(
"measure",
should_continue_injecting,
{"continue": "reason", "done": "report"}
)
graph.set_entry_point("observe")
graph.add_edge("report", END)
return graph.compile()
MCP Server Integration
Hermes exposes system-interaction capabilities as MCP (Model Context Protocol) servers — making them natively callable by LLM agents as structured tools:
from mcp.server import Server
from mcp.types import Tool
chaos_server = Server("hermes-chaos-injector")
@chaos_server.list_tools()
async def list_tools():
return [
Tool(name="inject_latency", description="Add latency to a service endpoint"),
Tool(name="kill_pod", description="Terminate a Kubernetes pod"),
Tool(name="exhaust_memory", description="Trigger OOM conditions on a container"),
Tool(name="drop_packets", description="Simulate partial network partition"),
Tool(name="query_metrics", description="Fetch real-time error rates and latency"),
Tool(name="inspect_topology", description="Map service dependencies and traffic"),
]
Key Design Decisions
Why LangGraph over a Simple Chain?
Traditional LangChain chains are linear — input flows through a fixed sequence of steps. Chaos engineering is inherently iterative: you inject a fault, observe what happens, decide whether to escalate or try a different vector, and loop. LangGraph's stateful graph execution with conditional edges maps naturally onto this loop — the agent can decide to inject another fault, back off, or terminate based on what it observes.
Why MCP for Tool Exposure?
MCP provides a standardized protocol for exposing system tools to LLM agents — with structured schemas, type-safe parameters, and clear capability declarations. Rather than embedding infrastructure calls as ad hoc Python functions inside the LLM chain, MCP servers give the agent a well-defined, introspectable tool registry. This also makes it straightforward to add new fault injection capabilities (e.g., DNS failures, certificate expiry) without modifying the core agent logic.
Structured Fault Reports
Every chaos run produces a structured JSON report:
{
"run_id": "hermes-2025-03-15-001",
"target_service": "payment-processor",
"duration_seconds": 847,
"faults_injected": [
{
"type": "latency",
"target": "auth-service → payment-processor",
"value_ms": 450,
"system_response": "cascading timeout in checkout flow",
"severity": "HIGH"
}
],
"resilience_gaps": [
{
"finding": "No circuit breaker on payment-processor → inventory-service call",
"impact": "Timeout cascade under auth latency injection",
"recommendation": "Add circuit breaker with 200ms timeout threshold"
}
]
}
Results & Insights
Running Hermes against a sample microservices deployment surfaced several failure modes that had not been scripted in existing chaos test suites:
- Timeout cascades triggered by upstream latency injection propagating through synchronous call chains with no circuit breakers
- Retry storms where aggressive retry policies under partial failure amplified load rather than improving resilience
- Split-brain conditions in stateful services when network partition scenarios were combined with leader election timeouts
These are precisely the class of failures that are easy to miss in manually scripted chaos tests — they emerge from interactions between components, not individual component failures.
What's Next
Hermes is designed to be extended. Planned capabilities include:
- GitOps integration — automatically open PRs with remediation suggestions derived from resilience reports
- Continuous background chaos — low-intensity, always-on fault injection in staging environments
- Multi-agent coordination — separate observer and injector agents with different LLMs to reduce reasoning bias
- Custom topology adapters — support for non-Kubernetes environments (VMs, serverless, bare metal)